|
Fabio Poiesi I'm the Head of the Technologies of Vision Lab at Fondazione Bruno Kessler in Trento, Italy. I'm also an Affiliated Researcher at the Istituto Italiano di Tecnologia, and teach Deep Learning for Computer Vision at the Shandong University. My research interests are computer vision and robot learning. I love solving challenging new research and industrial problems. In the last few years my focus has been on 3D scene understanding, object 6D pose estimation, 3D large multimodal models, and robot learning. In 2024, I launched the Computer Vision Trento Symposium, a major recurring computer vision event in northern Italy. I am an ELLIS Member, and serve as an Area Chair for several conferences, including CVPR and ECCV. Email / Google Scholar / X / Linkedin / github |

|
|
Sections: Journals, Conferences, Seminars. Check Google Scholar for the most updated list of publications. 🔥 New challenge: Check out the UNOBench Challenge (ECCV 2026 ODEWM Workshop) — benchmark your VLM on obstruction-aware robotic grasping reasoning. Final submissions due August 30, 2026. |
Selected journal papers |
|
High-resolution open-vocabulary object 6D pose estimation
J Corsetti, D Boscaini, F Giuliari, C Oh, A Cavallaro, F Poiesi IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), Oct 2025 We present an open-vocabulary VLM-based architecture that addresses relative pose estimation between two scenes of an unseen object, described by a textual prompt only. |

|
Multimodal Fusion SLAM with Fourier Attention
Y Zhou, G Mei, Y Wang, Y Wan, F Poiesi IEEE Robotics and Automation Letters (RAL), Feb 2025 (github) We present an efficient multimodal fusion SLAM method that utilizes Fast Fourier Transform to enhance the algorithm efficiency. |
|
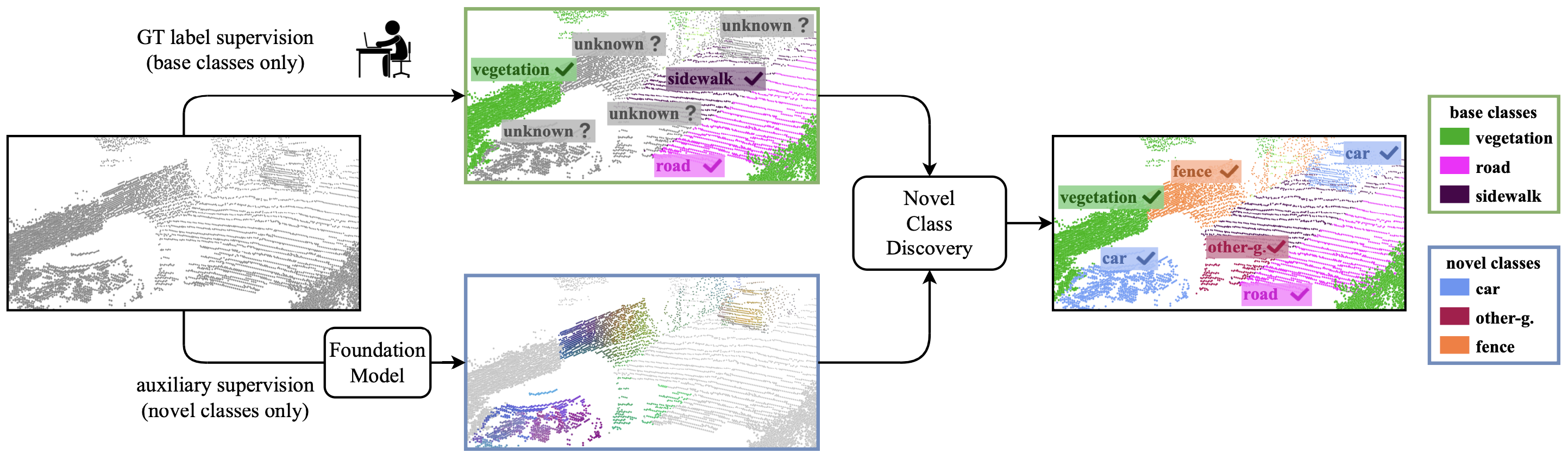
Novel class discovery meets foundation models for 3D semantic segmentation
L Riz, C Saltori, Y Wang, E Ricci, F Poiesi International Journal of Computer Vision (IJCV), Jun 2024 (website) We introduce the novel task of Novel Class Discovery (NCD) for point cloud semantic segmentation and present a new NCD approach based on online clustering, uncertainty estimation, and semantic distillation. |

|
Unsupervised Point Cloud Representation Learning by Clustering and Neural Rendering
G Mei, C Saltori, E Ricci, N Sebe, Q Wu, J Zhang, F Poiesi International Journal of Computer Vision (IJCV), Mar 2024 Augmentation-free unsupervised approach for point clouds to learn transferable point-level features by leveraging uni-modal information for soft clustering and cross-modal information for neural rendering. |
|
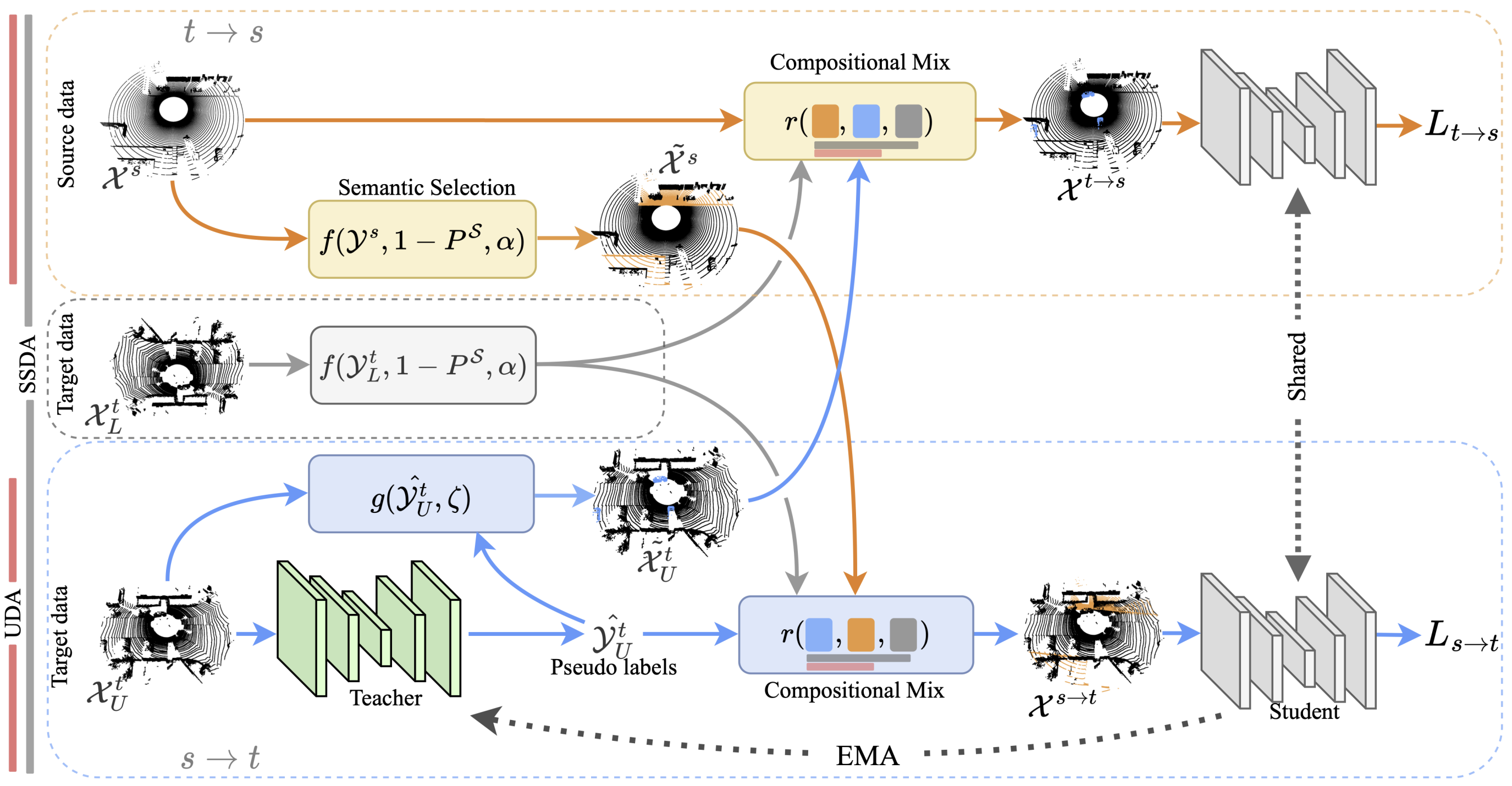
Compositional Semantic Mix for Domain Adaptation in Point Cloud Segmentation
C Saltori, F Galasso, G Fiameni, N Sebe, F Poiesi, E Ricci IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), Dec 2023 (github) Compositional semantic mixing for point cloud domain adaptation, representing the first unsupervised domain adaptation technique for point cloud segmentation based on semantic and geometric sample mixing. |
|
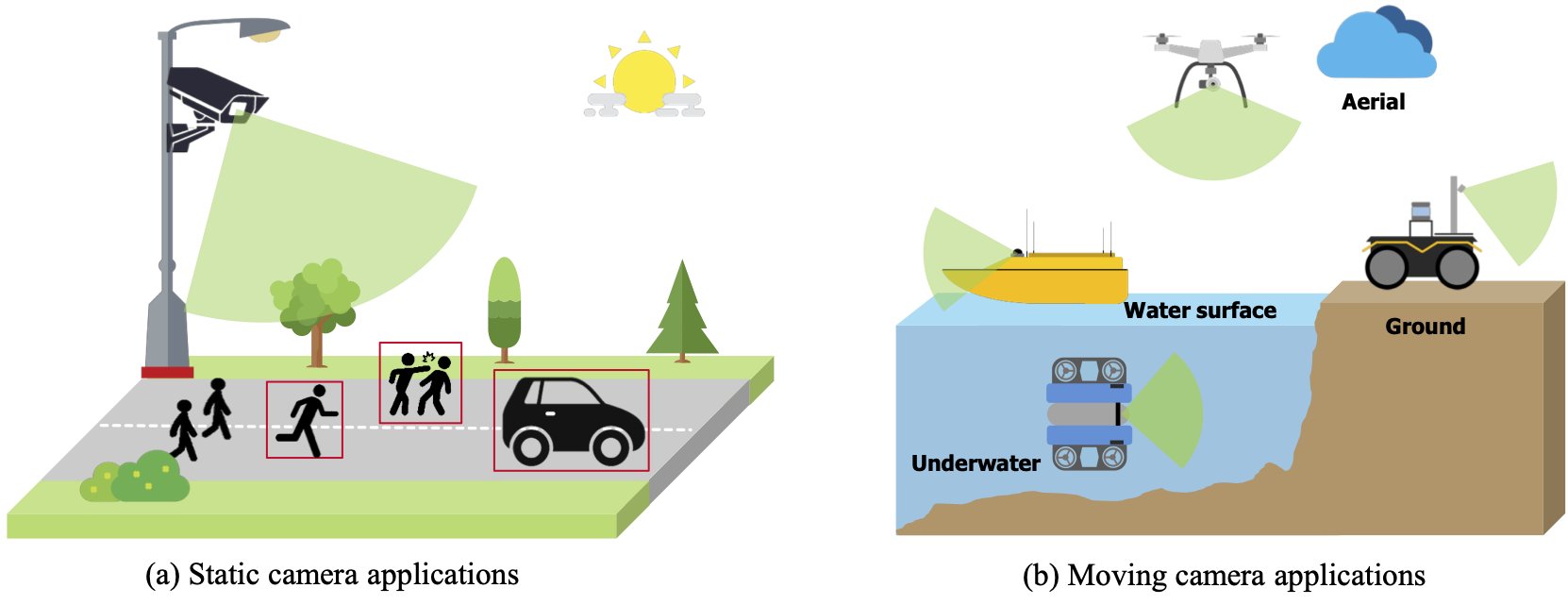
Survey on video anomaly detection in dynamic scenes with moving cameras
R Jiao, Y Wan, F Poiesi, Y Wang Artificial Intelligence Review, Oct 2023 First comprehensive survey on Moving Camera Video Anomaly Detection (MC-VAD). We delve into the research papers related to MC-VAD, critically assessing their limitations and highlighting associated challenges. |

|
PatchMixer: Rethinking network design to boost generalization for 3D point cloud understanding
D Boscaini, F Poiesi Image and Vision Computing (IMAVIS), Sep 2023 (github) Simple yet effective architecture that extends the ideas behind MLP-Mixer to 3D point clouds. We process local patches instead of the whole shape to promote robustness to partial point clouds. |

|
Attentive Multimodal Fusion for Optical and Scene Flow
Y Zhou, G Mei, Y Wang, F Poiesi, Y Wan IEEE Robotics and Automation Letters (RAL), Jul 2023 (github) Deep neural network to estimate optical flow based on early-stage information fusion between sensor modalities (RGB and depth). We incorporate self- and cross-attention layers at different network levels to construct informative features that leverage the strengths of both modalities. |
|
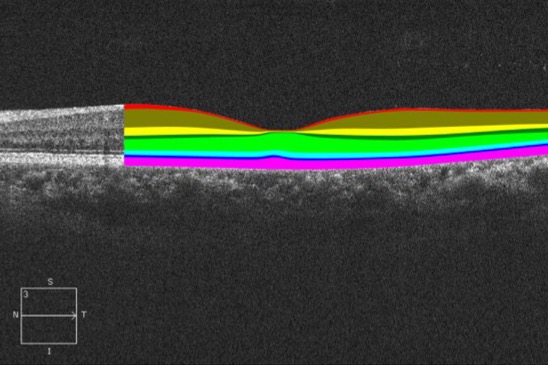
Exploiting multi-granularity visual features for retinal layer segmentation in human eyes
X He, Y Wang, F Poiesi, W Song, Q Xu, Z Feng, Y Wan Frontiers in Bioengineering and Biotechnology, Jun 2023 (github) End-to-end retinal layer segmentation network based on ConvNeXt that can retain more feature map details by using a new depth-efficient attention module and multiscale structures. |

|
Learning general and distinctive 3D local deep descriptors for point cloud registration
F Poiesi, D Boscaini IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), Mar 2023 (github) Method to learn general and distinctive 3D local descriptors that can be used to register point clouds that are captured in different domains. |

|
Loop closure detection using local 3D deep descriptors
Y Zhou, Y Wang, F Poiesi, Q Qin, Y Wan IEEE Robotics and Automation Letters (RAL), Jul 2022 Simple yet effective method to address loop closure detection in simultaneous localisation and mapping using local 3D deep descriptors (L3Ds). L3Ds are emerging com- pact representations of patches extracted from point clouds that are learnt from data using a deep learning algorithm. |

|
Performance comparison of image enhancers with and without deep learning
M Lecca, F Poiesi Journal of the Optical Society of America A (JOSA), Apr 2022 We empirically compare a set of traditional and deep learning enhancers, which we selected as representing different methodologies for the improvement of bad illuminated images. |
|
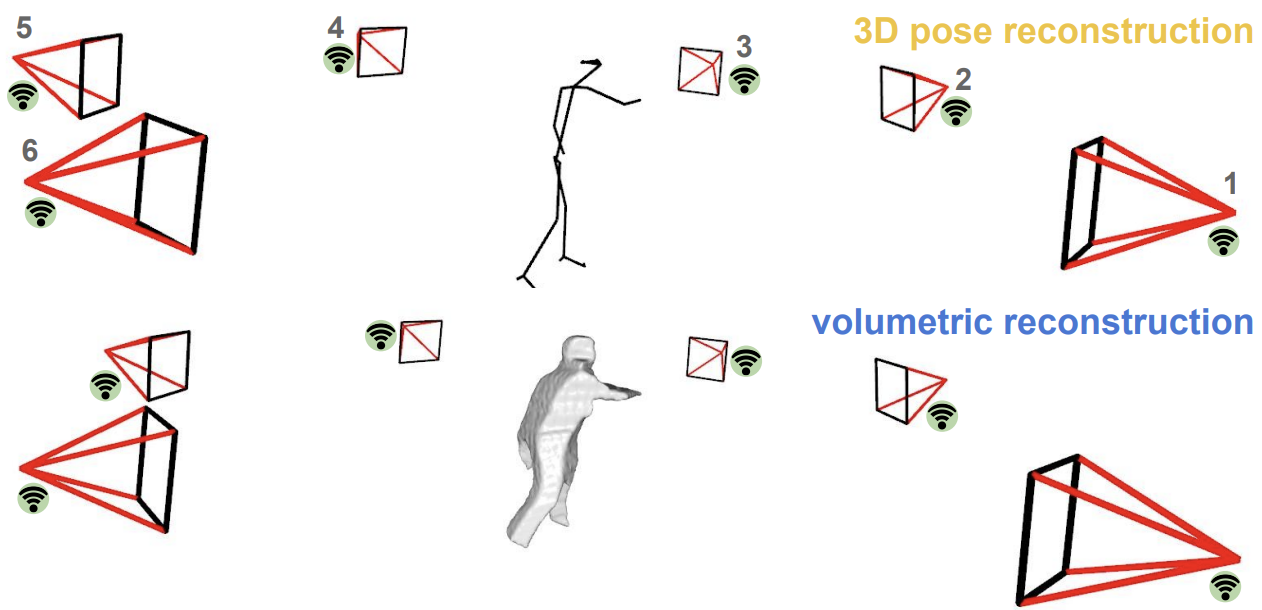
Multi-view data capture for dynamic object reconstruction using handheld augmented reality mobiles
M Bortolon, L Bazzanella, F Poiesi Journal of Real-Time Image Processing (JRTIP), Mar 2021 (github) System to capture nearlysynchronous frame streams from multiple and moving handheld mobiles that is suitable for dynamic object 3D reconstruction. Each mobile executes Simultaneous Localisation and Mapping on-board to estimate its pose, and uses a wireless communication channel to send or receive synchronisation triggers. |

|
Support Vector Motion Clustering
I A Lawal, F Poiesi, D Anguita, A Cavallaro IEEE Trans. on Circuits and Systems for Video Technology (TCSVT), Nov 2017 Closed-loop unsupervised clustering method for motion vectors extracted from highly dynamic video scenes. Motion vectors are assigned to non-convex homogeneous clusters characterizing direction, size and shape of regions with multiple independent activities. |

|
Tracking multiple high-density homogeneous targets
F Poiesi, A Cavallaro IEEE Trans. on Circuits and Systems for Video Technology (TCSVT), Apr 2015 (video) Framework for multi-target detection and tracking that infers candidate target locations in videos containing a high density of homogeneous targets. |

|
Predicting and recognizing human interactions in public spaces
F Poiesi, A Cavallaro Journal on Real-Time Image Processing (JRTIP), Dec 2015 Method for predicting rendezvous areas in observable and unobservable regions using sparse motion information. Rendezvous areas indicate where people are likely to interact with each other or with static objects (e.g. a door, an information desk or a meeting point). |

|
Measures of effective video tracking
T Nawaz, F Poiesi, A Cavallaro IEEE Trans. on Image Processing (TIP), Jan 2014 (video) Three parameter-independent measures for evaluating multi-target video tracking. The measures take into account target-size variations, combine accuracy and cardinality errors, quantify long-term tracking accuracy at different accuracy levels, and evaluate ID changes relative to the duration of the track in which they occur. |

|
Multi-target tracking on confidence maps: an application to people tracking
F Poiesi, R Mazzon, A Cavallaro Computer Vision and Image Understanding (CVIU), Oct 2013 (video) Generic online multi-target track-before-detect based on particle filtering that is applicable on confidence maps used as observations. We include the target ID into the particle state, enabling tracking with unknown and large number of targets. |
Selected conference papers |

|
Obstruction reasoning for robotic grasping
Runyu Jiao, Matteo Bortolon, Francesco Giuliari, Alice Fasoli, Sergio Povoli, Guofeng Mei, Yiming Wang, Fabio Poiesi Computer Vision and Pattern Recognition (CVPR), Jun 2026 (website) UNOGrasp performs multi-step obstruction reasoning for robotic grasping in cluttered scenes. Given an RGB-D image and a natural-language goal (e.g., grasp the white iphone box), UNOGrasp reasons and grounds spatial information to infer the sequence of steps to unobstruct a requested object. |
|
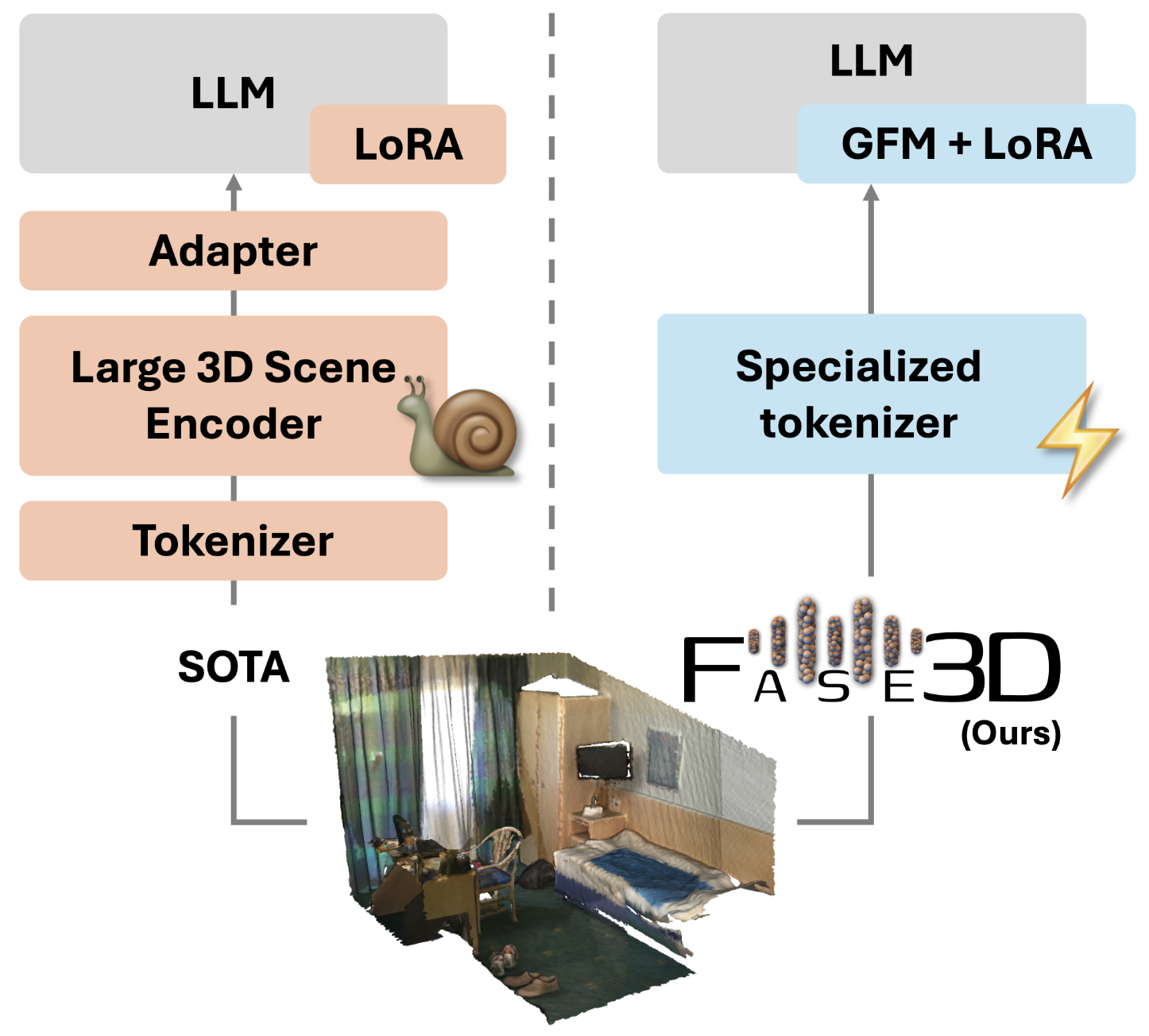
Efficient Encoder-Free Fourier-based 3D Large Multimodal Model
Guofeng Mei, Wei Lin, Luigi Riz, Yujiao Wu, Yiming Wang, Fabio Poiesi Computer Vision and Pattern Recognition (CVPR), Jun 2026 (website) Fase3D eliminates the redundancy of most 3D large multimodal models (LMMs) that rely on computationally heavy scene encoders to extract geometric features. By employing a lightweight Fourier-based tokenizer and Fourier-augmented LoRA adapters, Fase3D processes raw point clouds directly. |
|
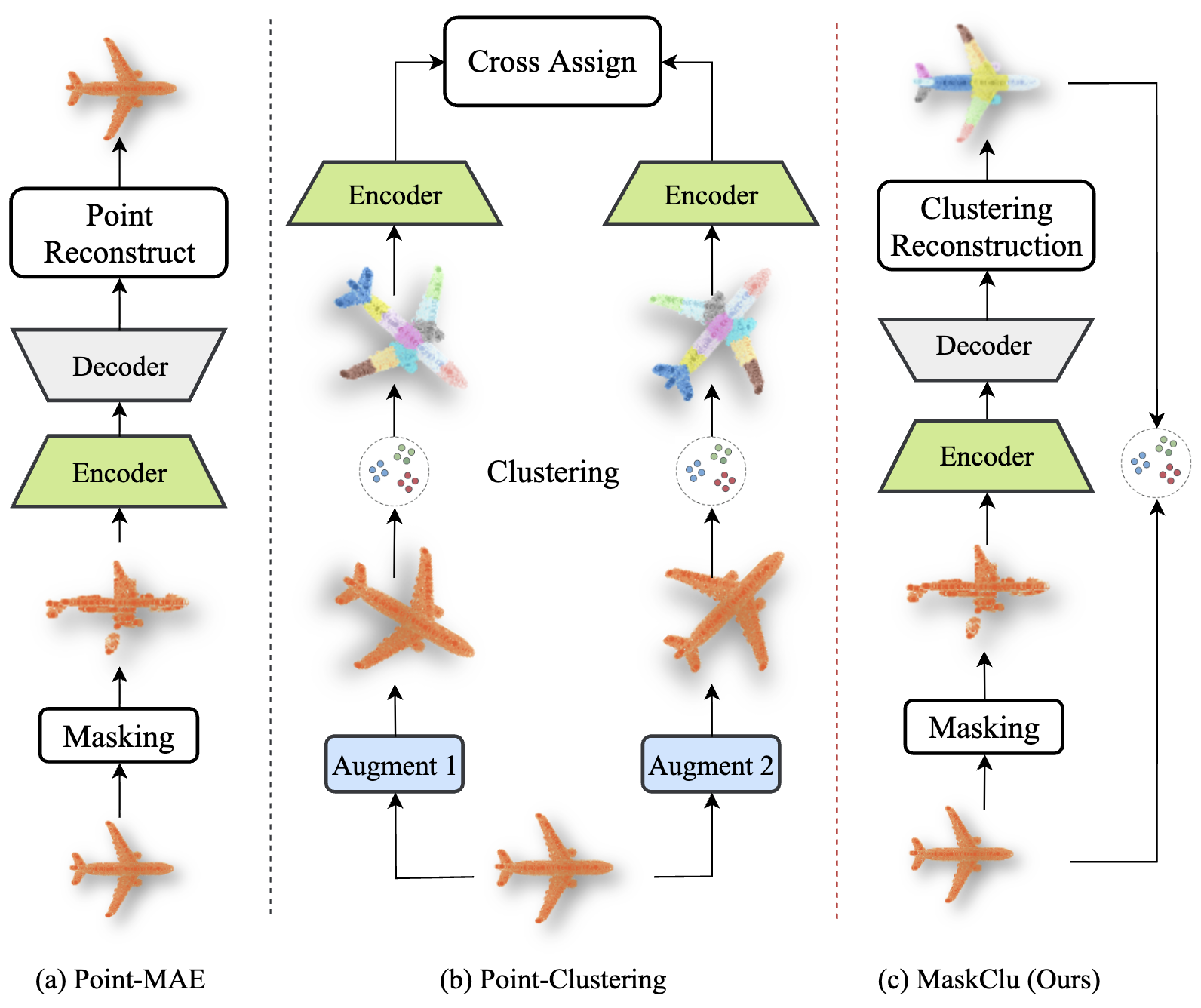
Masked Clustering Prediction for Unsupervised Point Cloud Pre-training
Bin Ren, Xiaoshui Huang, Mengyuan Liu, Hong Liu, Fabio Poiesi, Nicu Sebe, Guofeng Mei Annual Conference on Neural Information Processing Systems (AAAI Oral), Jan 2026 (github) MaskClu combines the strengths of masked modeling and clustering-based learning to produce highly-informative point-level 3D representations. |
|
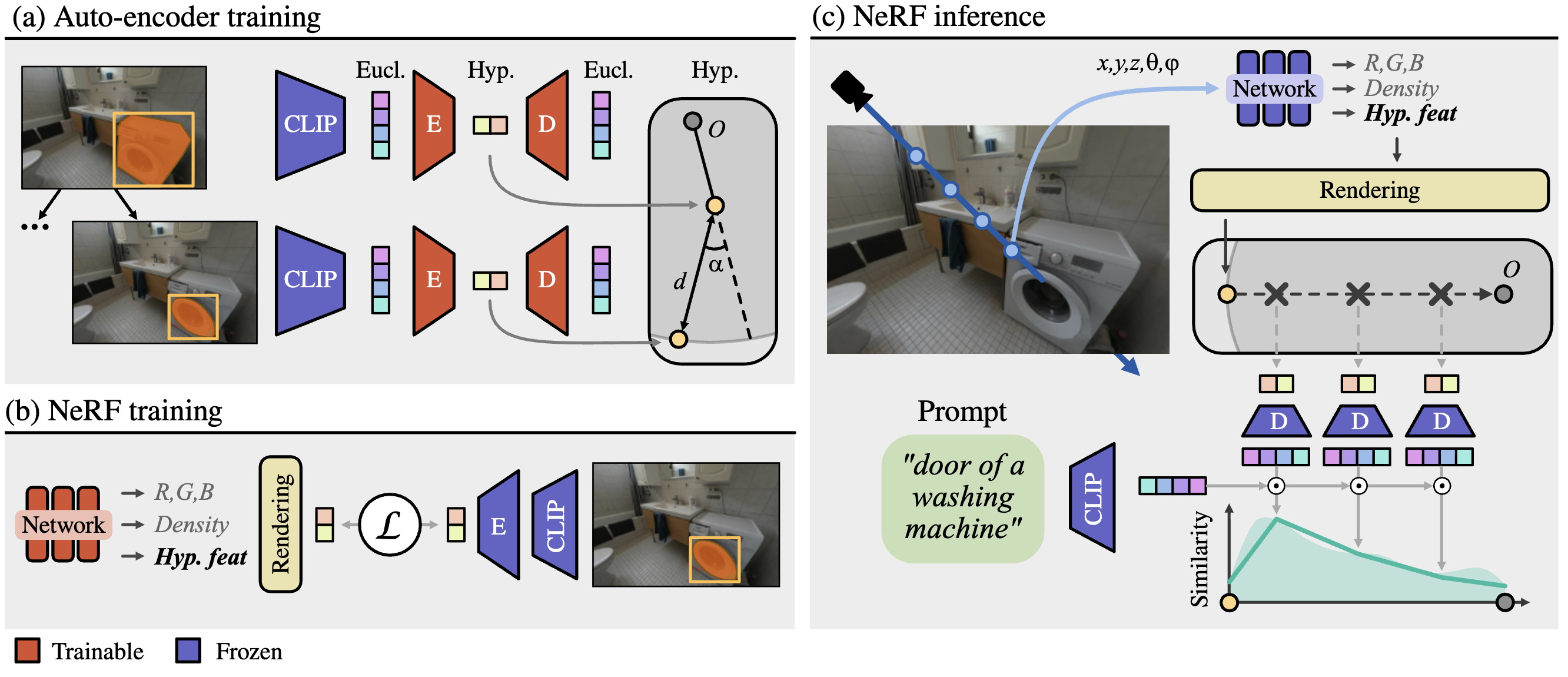
OpenHype: Hyperbolic Embeddings for Hierarchical Open-Vocabulary Radiance Fields
Lisa Weijler, Sebastian Koch, Fabio Poiesi, Timo Ropinski, Pedro Hermosilla Annual Conference on Neural Information Processing Systems (NeurIPS), Dec 2025 (website) OpenHype represents scene hierarchies using hyperbolic geometry, enabling multi-scale, open-vocabulary 3D scene representations. |
|
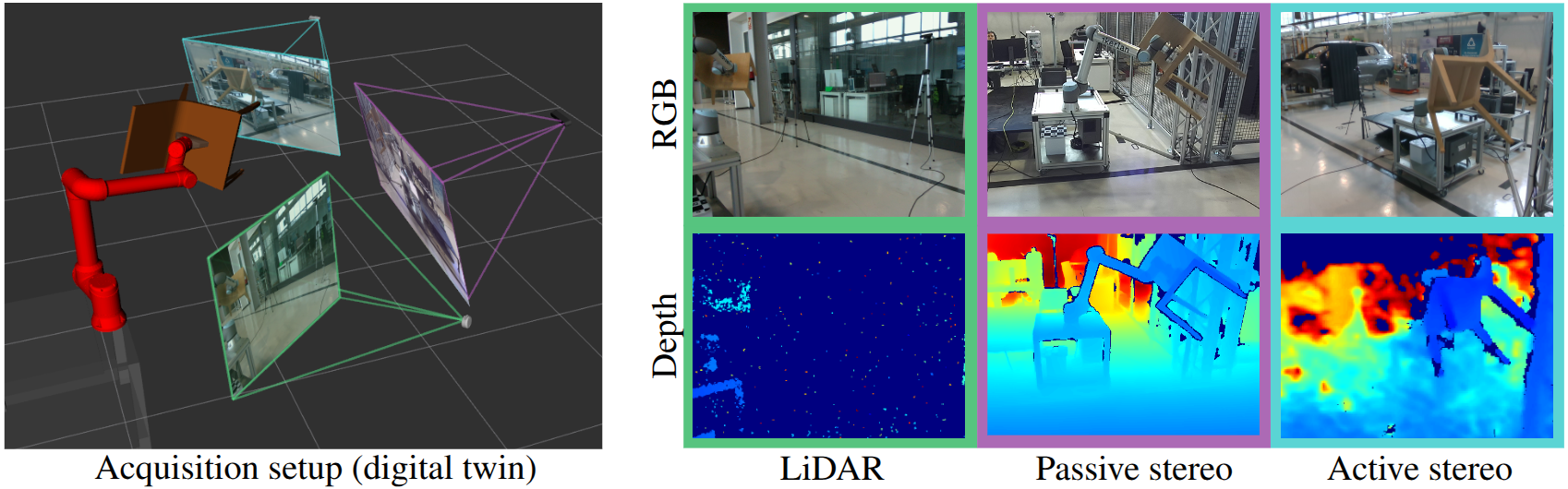
CHIP: A multi-sensor dataset for 6D pose estimation of chairs in industrial settings
Mattia Nardon, Mikel Mujika Agirre, Ander González Tomé, Daniel Sedano Algarabel, Josep Rueda Collell, Ana Paola Caro, Andrea Caraffa, Fabio Poiesi, Paul Ian Chippendale, Davide Boscaini British Machine Vision Conference (BMVC), Nov 2025 (website) The CHIP dataset features multi-sensor RGBD videos of a robotic arm manipulating wooden chairs in an industrial setting. The images are captured from multiple viewpoints and annotated with ground-truth 6D poses derived from the robot's kinematics, making it a valuable benchmark for evaluating 6D pose estimation methods in realistic scenarios. |
|
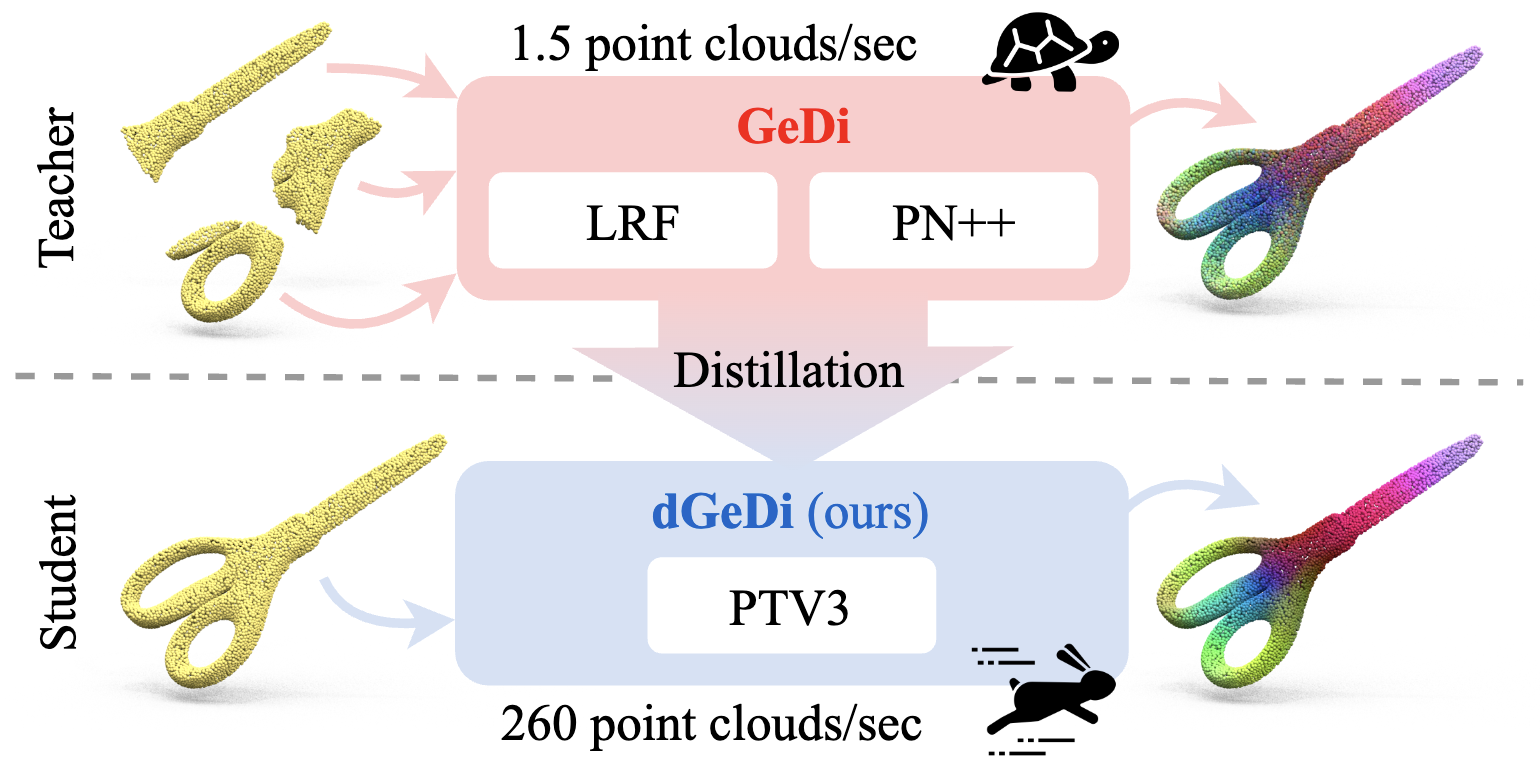
Distilling 3D distinctive local descriptors for 6D pose estimation
Amir Hamza, Andrea Caraffa, Davide Boscaini, Fabio Poiesi International Conference on Intelligent Robots and Systems (IROS), Oct 2025 (website) dGedi id a fast 3D point cloud encoder trained by distilling GeDi features. |

|
GRASPLAT: Enabling dexterous grasping through novel view synthesis
Matteo Bortolon, Nuno Ferreira Duarte, Plinio Moreno, Fabio Poiesi, Jose' Santos-Victor, Alessio Del Bue International Conference on Intelligent Robots and Systems (IROS), Oct 2025 (website) GRASPLAT is a grasping framework that synthesizes physically plausible images of a hand grasping an object and regresses the corresponding hand joints for a successful grasp. |

|
Free-form language-based robotic reasoning and grasping
Runyu Jiao, Alice Fasoli, Francesco Giuliari, Matteo Bortolon, Sergio Povoli, Guofeng Mei, Yiming Wang, Fabio Poiesi International Conference on Intelligent Robots and Systems (IROS), Oct 2025 (website) Performing robotic grasping from a cluttered bin based on human instructions is a challenging task, as it requires understanding both the nuances of free-form language and the spatial relationships between objects. FreeGrasp leverages pre-trained VLMs’ world knowledge to reason about human instructions and object spatial arrangements. |
|
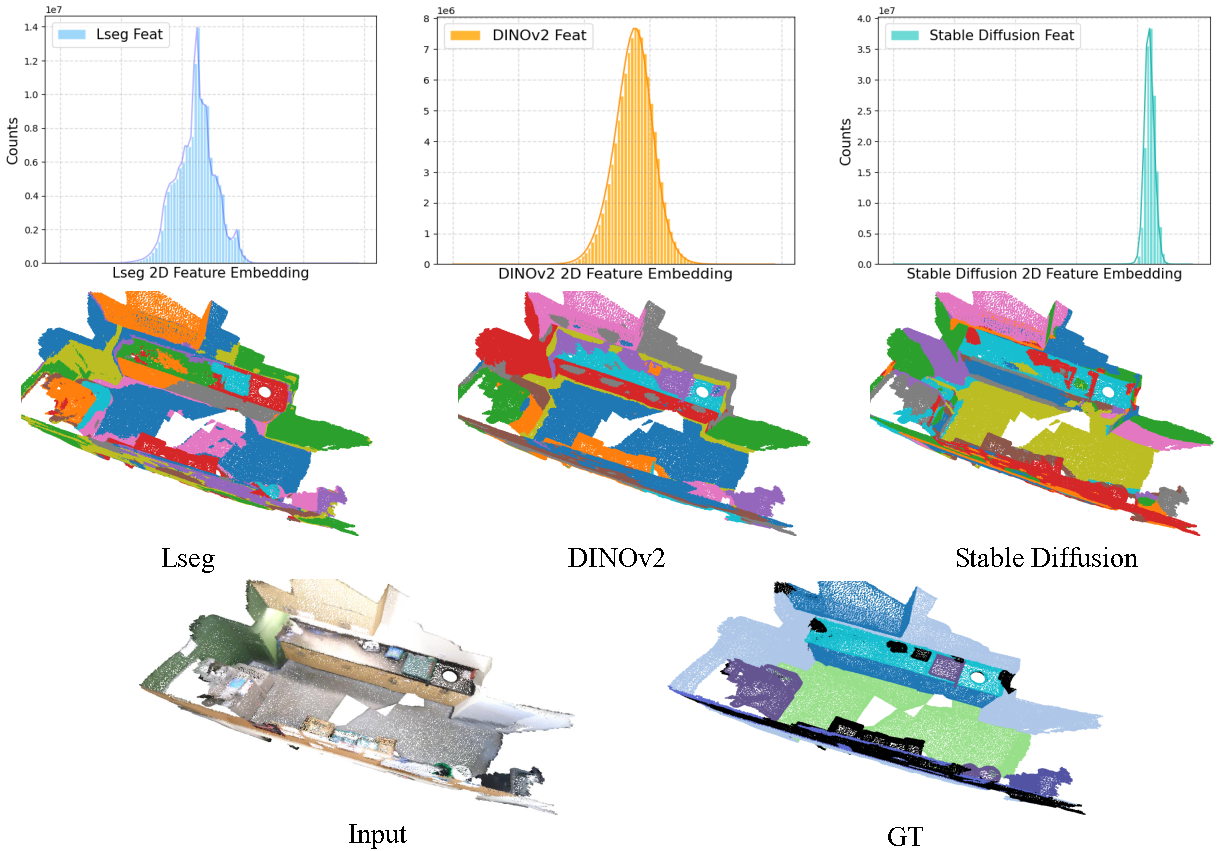
Cross-modal and uncertainty-aware agglomeration for open-vocabulary 3D scene understanding
Jinlong Li, Cristiano Saltori, Fabio Poiesi, Nicu Sebe Computer Vision and Pattern Recognition (CVPR), Jun 2025 (website) Cross-modal and Uncertainty-aware Agglomeration for Open-vocabulary 3D Scene Understanding (CUA-O3D) is the first model to integrate multiple foundation models—such as CLIP, DINOv2, and Stable Diffusion—into 3D scene understanding. |

|
PerLA: Perceptive 3D Language Assistant
Guofeng Mei, Wei Lin, Luigi Riz, Yujiao Wu, Fabio Poiesi, Yiming Wang Computer Vision and Pattern Recognition (CVPR), Jun 2025 (website) PerLA is a 3D language assistant designed to be more perceptive to both details and context, making visual representations more informative for the LLM. |
|
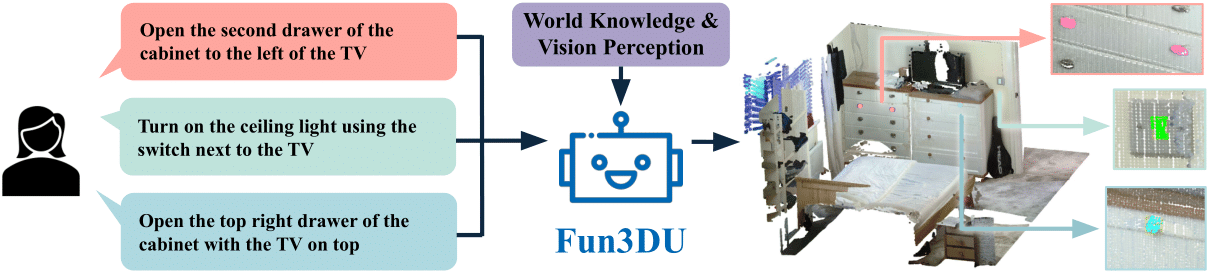
Functionality understanding and segmentation in 3D scenes
Jaime Corsetti, Francesco Giuliari, Alice Fasoli, Davide Boscaini, Fabio Poiesi Computer Vision and Pattern Recognition (CVPR Highlight), Jun 2025 (website) Fun3DU is the first approach designed for functionality understanding in 3D scenes. Understanding functionalities in 3D scenes involves interpreting natural language descriptions to locate functional interactive objects, such as handles and buttons, in a 3D environment. |
|
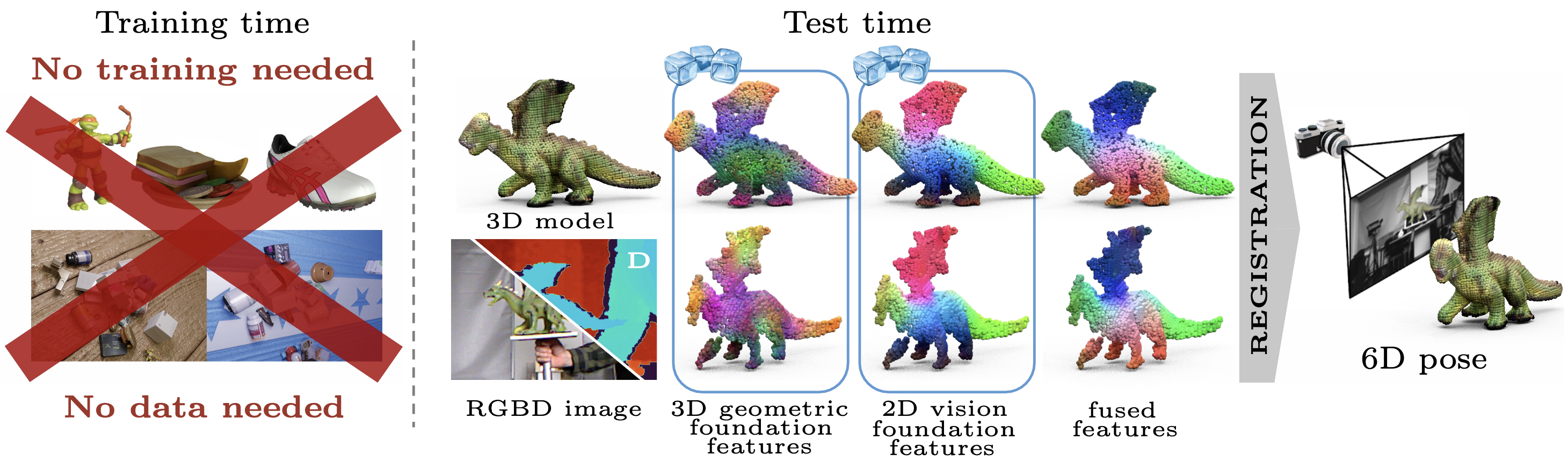
FreeZe: Training-free zero-shot 6D pose estimation with geometric and vision foundation models
Andrea Caraffa, Davide Boscaini, Amir Hamza, Fabio Poiesi European Conference on Computer Vision (ECCV), Sep 2024 (website) FreeZe estimates the 6D pose of a novel object by fusing contributions from pre-trained geometric and vision foundation models without requiring any task-specific training. We then estimate the 6D pose of unseen objects by 3D registration based on RANSAC. We also introduce a novel algorithm to solve ambiguous cases due to geometrically symmetric objects that is based on visual features. |
|
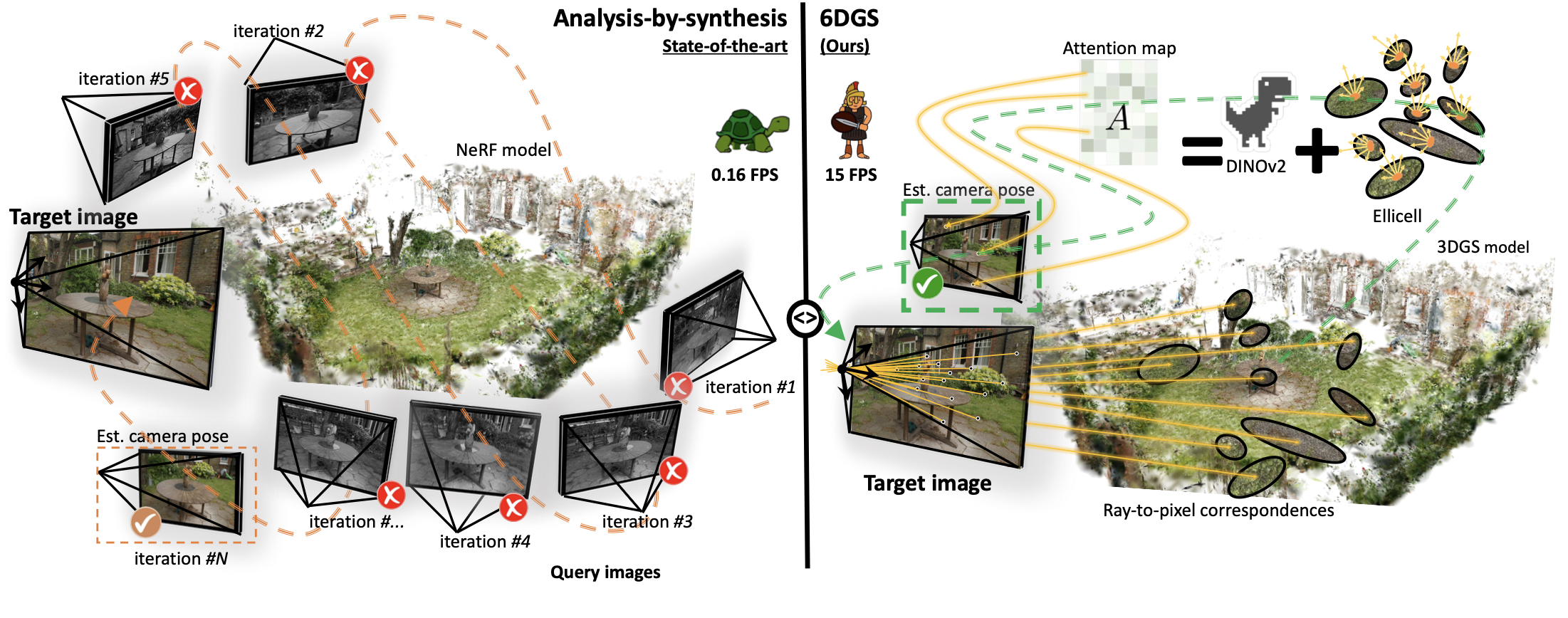
6DGS: 6D pose estimation from a single image and a 3D Gaussian Splatting model
Matteo Bortolon, Theodore Tsesmelis, Stuart James, Fabio Poiesi, Alessio Del Bue European Conference on Computer Vision (ECCV), Sep 2024 (website) Standard NeRF-based methods (left) employ an iterative process, rendering candidate poses and comparing them with the target image before updating the pose. 6DGS (right) estimates the camera pose by selecting a bundle of rays projected from the ellipsoid surface (a radiant Ellicell) and learning an attention map to output ray/image pixel correspondences (based on DINOv2). The optimal bundle of rays should intersect the optical center of the camera and then are used to estimate the camera rotation in closed-form. |

|
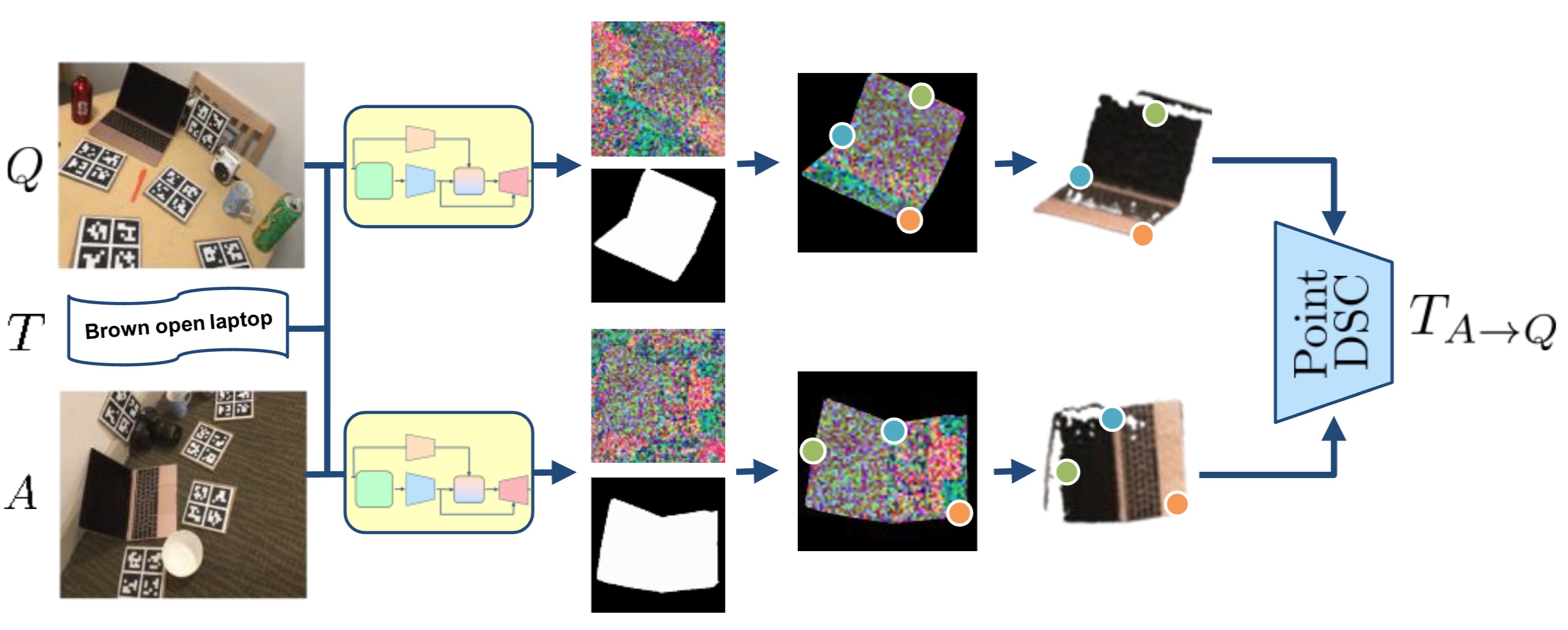
Open-vocabulary object 6D pose estimation
Jaime Corsetti, Davide Boscaini, Changjae Oh, Andrea Cavallaro, Fabio Poiesi Computer Vision and Pattern Recognition (CVPR Highlight), Jun 2024 (website) Our approach leverages a Vision-Language Model to segment the object of interest from two distinct scenes and to estimate its relative 6D pose. We assume (i) the object of interest is specified solely through the textual prompt, (ii) no object model (e.g. CAD or video sequence) is required at inference, (iii) the object is imaged from two different viewpoints of two different scenes, and (iv) the object was not observed during the training phase. |
|
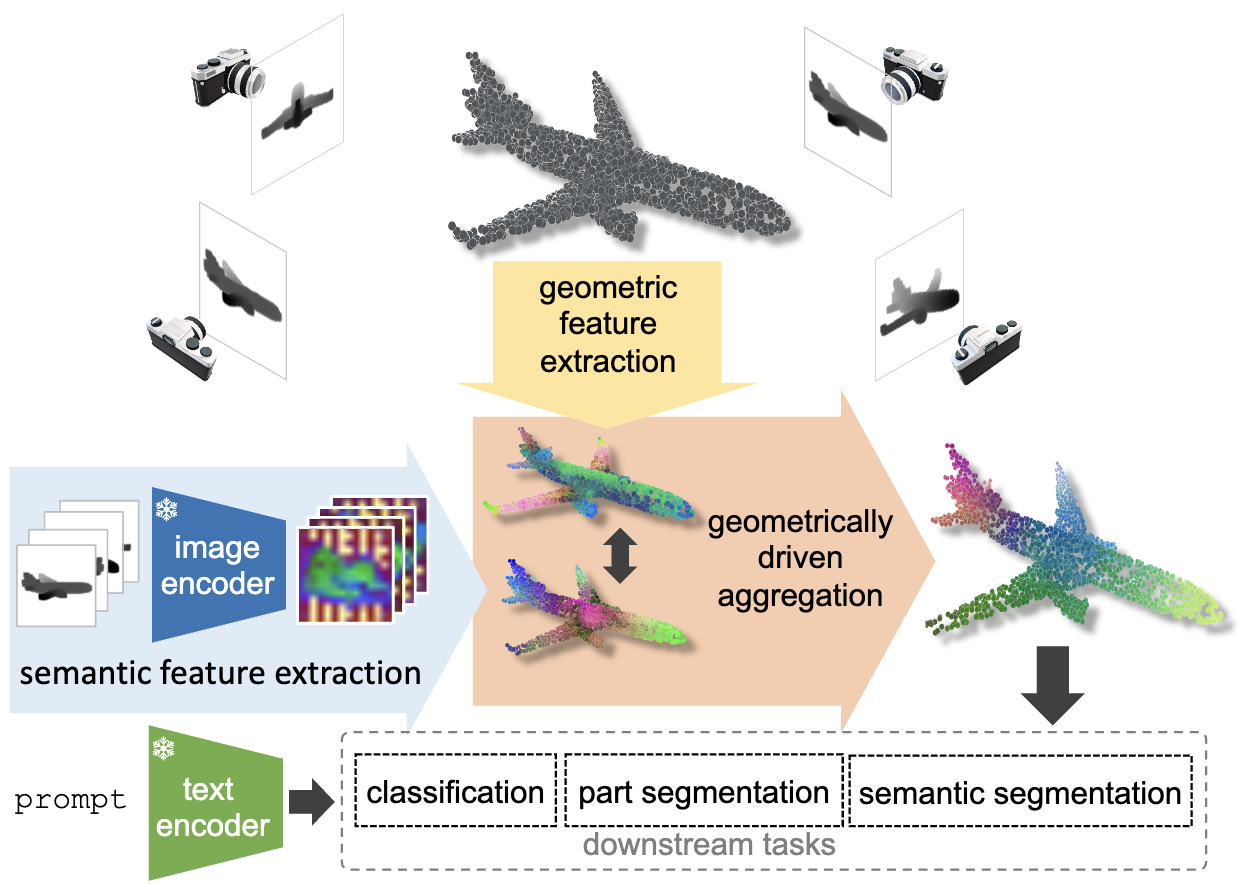
Geometrically-driven aggregation for zero-shot 3D point cloud understanding
Guofeng Mei, Luigi Riz, Yiming Wang, Fabio Poiesi Computer Vision and Pattern Recognition (CVPR Highlight), Jun 2024 (website) Training-free aggregation technique that leverages the point cloud's 3D geometric structure to improve the quality of the transferred Vision-Language Model representations. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. |
|
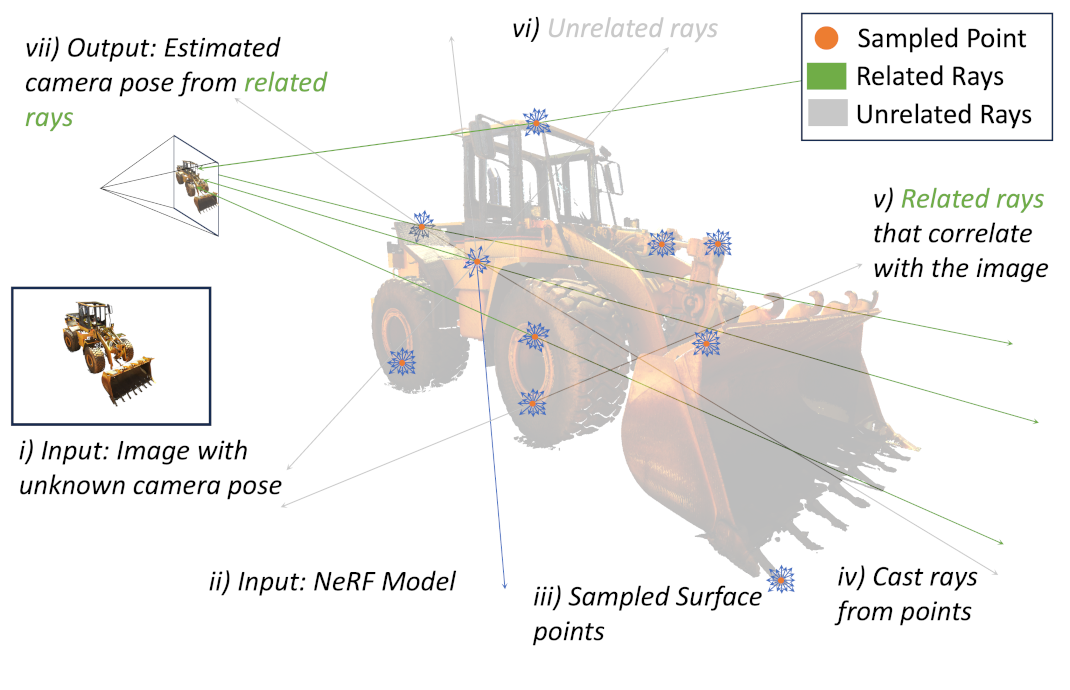
IFFNeRF: Initialisation Free and Fast 6DoF pose estimation from a single image and a NeRF model
Matteo Bortolon, Theodore Tsesmelis, Stuart James, Fabio Poiesi, Alessio Del Bue International Conference on Robotics and Automation (ICRA), May 2024 (website) From a given image with an unknown pose and a NeRF model, we recover the pose by first sampling surface points using Metropolis-Hasting algorithm and casting rays from them in isocell distribution. We then correlate rays with the image to identify relevant rays using attention and recover the unknown camera pose. |

|
Detect, Augment, Compose, and Adapt: Four Steps for Unsupervised Domain Adaptation in Object Detection
Mohamed L. Mekhalfi, Davide Boscaini, Fabio Poiesi British Machine Vision Conference (BMVC), Nov 2023 (github) Effective four-step unsupervised domain adaptation approach that leverages self-supervision and trains source and target data concurrently. |

|
Revisiting Fully Convolutional Geometric Features for Object 6D Pose Estimation
Jaime Corsetti, Davide Boscaini, Fabio Poiesi International Conference on Computer Vision Workshops (ICCVW), Oct 2023 (github) Revisiting Fully Convolutional Geometric Features (FCGF) to achieve object 6D pose estimation state-of-the-art performance. FCGF employs sparse convolutions and learns point-level features using a fully-convolutional network by optimising a hardest contrastive loss. |
|
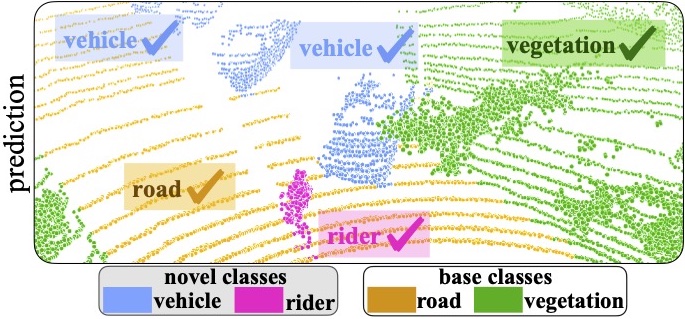
Novel Class Discovery for 3D Point Cloud Semantic Segmentation
Luigi Riz, Cristiano Saltori, Elisa Ricci, Fabio Poiesi Computer Vision and Pattern Recognition (CVPR), Jun 2023 (github) Method for novel class discovery for 3D point clouds based on online clustering exploiting uncertainty quantification to produce prototypes for pseudo-labelling points of novel classes. |

|
The MONET dataset: Multimodal drone thermal dataset recorded in rural scenarios
Luigi Riz, Andrea Caraffa, Matteo Bortolon, Mohamed Lamine Mekhalfi, Davide Boscani, Andre Moura, Jose Antunes, Andre Dias, Hugo Silva, Andreas Leonidou, Christos Constantinides, Christos Keleshis, Dante Abate, Fabio Poiesi Computer Vision and Pattern Recognition Workshops (CVPRW), Jun 2023 (github) MONET is a multimodal dataset captured using a thermal camera mounted on a drone that flew over rural areas, and recorded human and vehicle activities. |

|
Overlap-guided Gaussian Mixture Models for Point Cloud Registration
Guofeng Mei, Fabio Poiesi, Cristiano Saltori, Jian Zhang, Elisa Ricci, Nicu Sebe Winter Conference on Applications of Computer Vision (WACV), Jan 2023 (github) Overlap-guided probabilistic registration approach that computes the optimal transformation from matched Gaussian Mixture Model parameters. |
|
Data Augmentation-free Unsupervised Learning for 3D Point Cloud Understanding
Guofeng Mei, Cristiano Saltori, Fabio Poiesi, Jian Zhang, Elisa Ricci, Nicu Sebe, Qiang Wu British Machine Vision Conference (BMVC), Nov 2022 (github) Augmentation-free unsupervised approach for point clouds to learn transferable point-level features via soft clustering. |
|
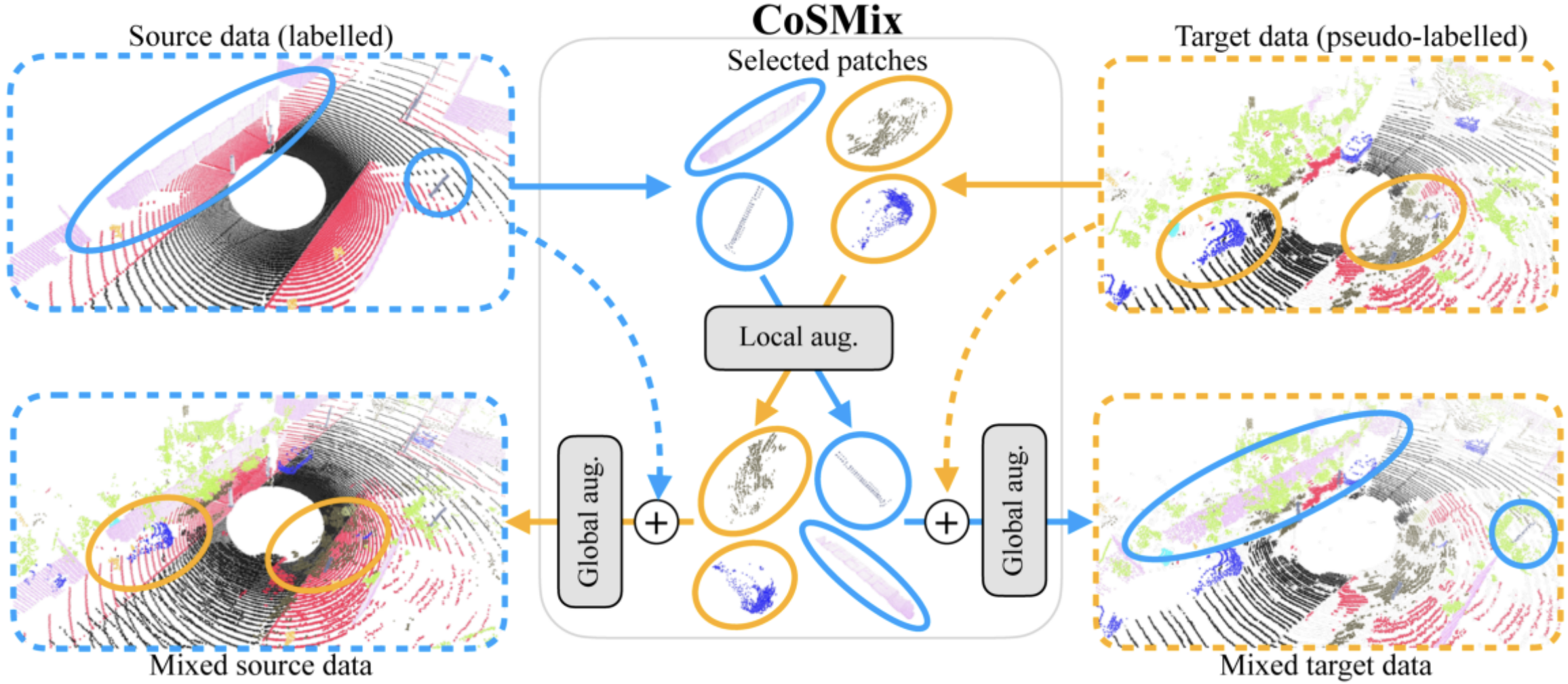
CoSMix: Compositional semantic mix for domain adaptation in 3D LiDAR segmentation
Cristiano Saltori, Fabio Galasso, Giuseppe Fiameni, Nicu Sebe, Elisa Ricci, Fabio Poiesi European Conference on Computer Vision (ECCV), Oct 2022 (github) Sample mixing for point cloud unsupervised domain adaptation, namely Compositional Semantic Mix (CoSMix), the first UDA approach for point cloud segmentation based on sample mixing. |
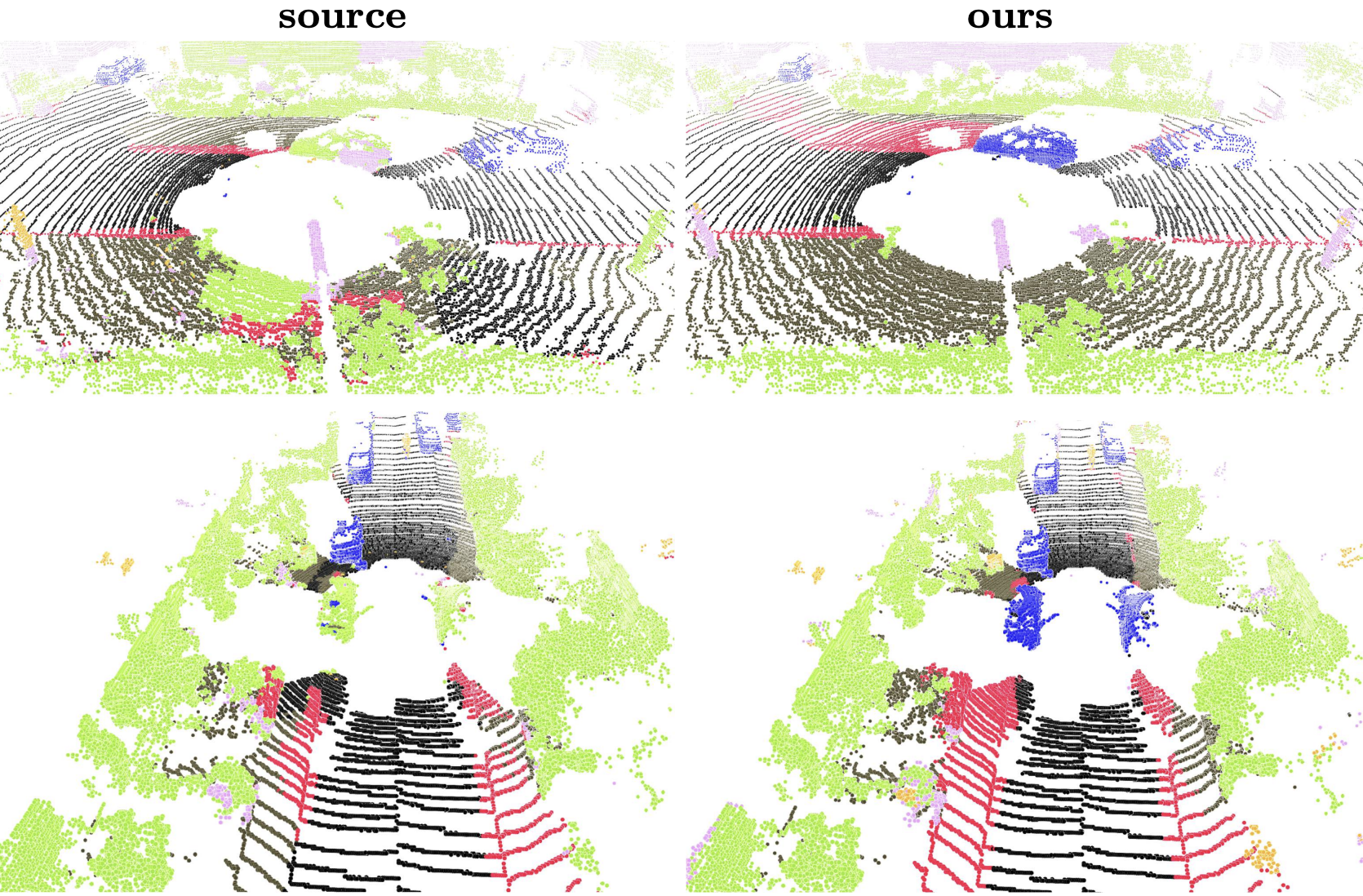
|
GIPSO: Geometrically Informed Propagation for Online Adaptation in 3D LiDAR Segmentation
Cristiano Saltori, Evgeny Krivosheev, Stephane Lathuiliere, Nicu Sebe, Fabio Galasso, Giuseppe Fiameni, Elisa Ricci, Fabio Poiesi European Conference on Computer Vision (ECCV), Oct 2022 (github) Adaptive self-training and geometric-feature propagation to adapt a pre-trained source model online without requiring either source data or target labels. |

|
Distinctive 3D local deep descriptors
Davide Boscaini, Fabio Poiesi International Conference on Pattern Recognition (ICPR), Jan 2021 (github) Learning distinctive 3D local deep descriptors (DIPs) that can be used to register point clouds without requiring an initial alignment. |
|
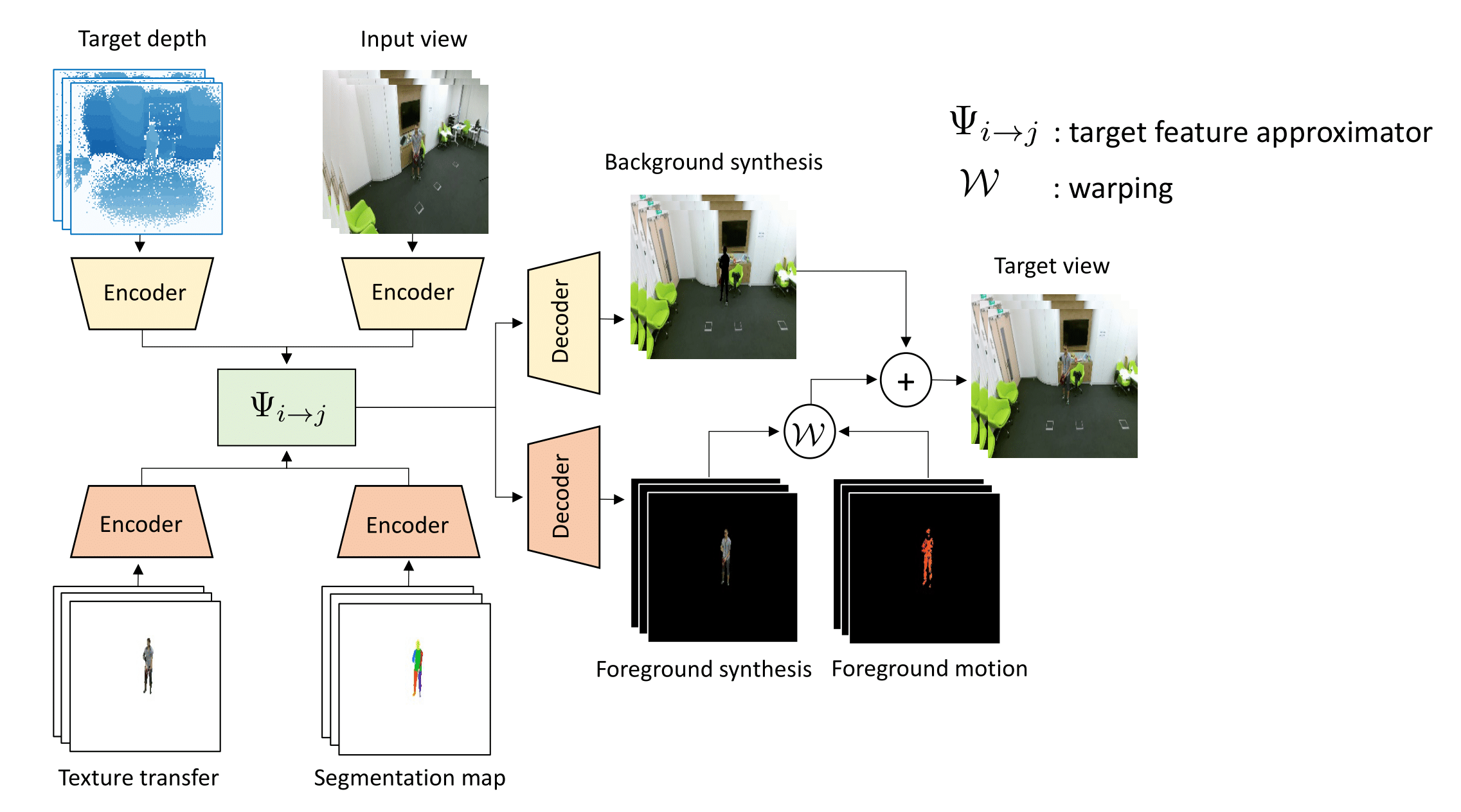
Novel-View Human Action Synthesis
Mohamed I. Lakhal, Davide Boscaini, Fabio Poiesi, Oswald Lanz, Andrea Cavallaro Asian Conference on Computer Vision (ACCV), Nov 2020 (project page) Novel-View Human Action Synthesis aims to synthesize the movement of a body from a virtual viewpoint, given a video from a real viewpoint. We employ 3D reasoning to synthesize the target viewpoint. |

|
Seamless bare-hand interaction in Mixed Reality
Caterina Battisti, Stefano Messelodi, Fabio Poiesi International Symposium on Mixed and Augmented Reality (ISMAR), Oct 2018 (video) Unrealistic Mixed Reality (MR) experiences can be caused by unprocessed occlusions between real and augmented objects during interactions. This can be addressed by blending real-time 3D finger tracking information with the visualisation of the hand in MR. |
|
A distributed vision-based consensus model for aerial-robotic teams
Fabio Poiesi, Andrea Cavallaro Intelligent Robot and Systems (IROS), Oct 2018 (video) Distributed model for a team of autonomous aerial robots to collaboratively track a target without external control. The model uses distributed consensus to coordinate actions and to maintain formation via geometric constraints. |

|
Cloud-based collaborative 3D reconstruction using smartphones
Fabio Poiesi, Alex Locher, Paul Chippendale, Erica Nocerino, Fabio Remondino, Luc Van Gool European Conference on Visual Media Production (CVMP Oral), Dec 2017 (video) Pipeline that enables multiple users to collaboratively acquire images with monocular smartphones and derive a 3D point cloud using a remote reconstruction server. |

|
Online multi-target tracking with strong and weak detections
Ricardo Sanchez-Matilla, Fabio Poiesi, Andrea Cavallaro European Conference on Computer Vision Workshops (ECCVW), Oct 2016 Online multi-target tracker that exploits both high- and low-confidence target detections in a Probability Hypothesis Density Particle Filter. High-confidence detections are used for label propagation and target initialization. Low-confidence detections only support tracking existing targets. |
|
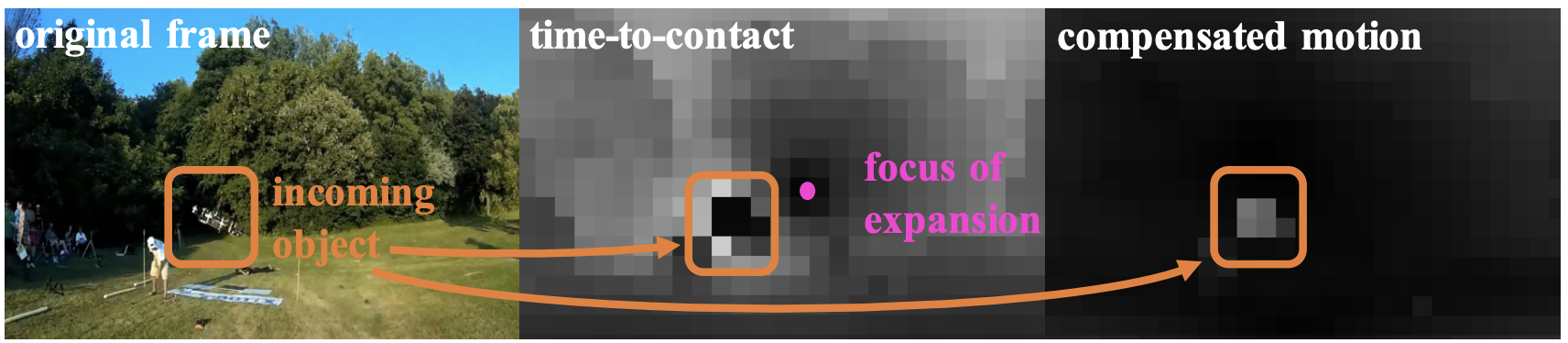
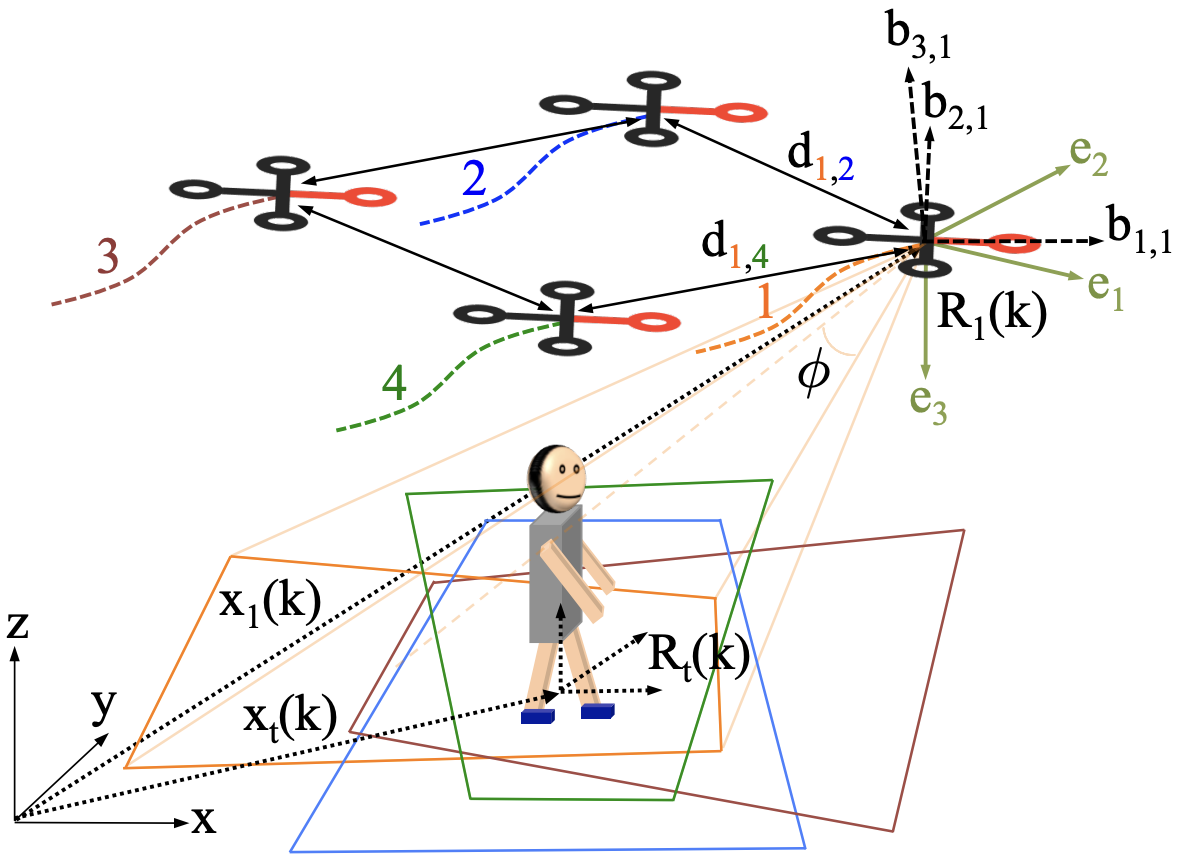
Detection of fast incoming objects with a moving camera
Fabio Poiesi, Andrea Cavallaro British Machine Vision Conference (BMVC Oral), Sep 2016 (source code) Moving object detection and avoidance algorithm for an uncalibrated camera that uses only the optical flow to predict collisions. |
|
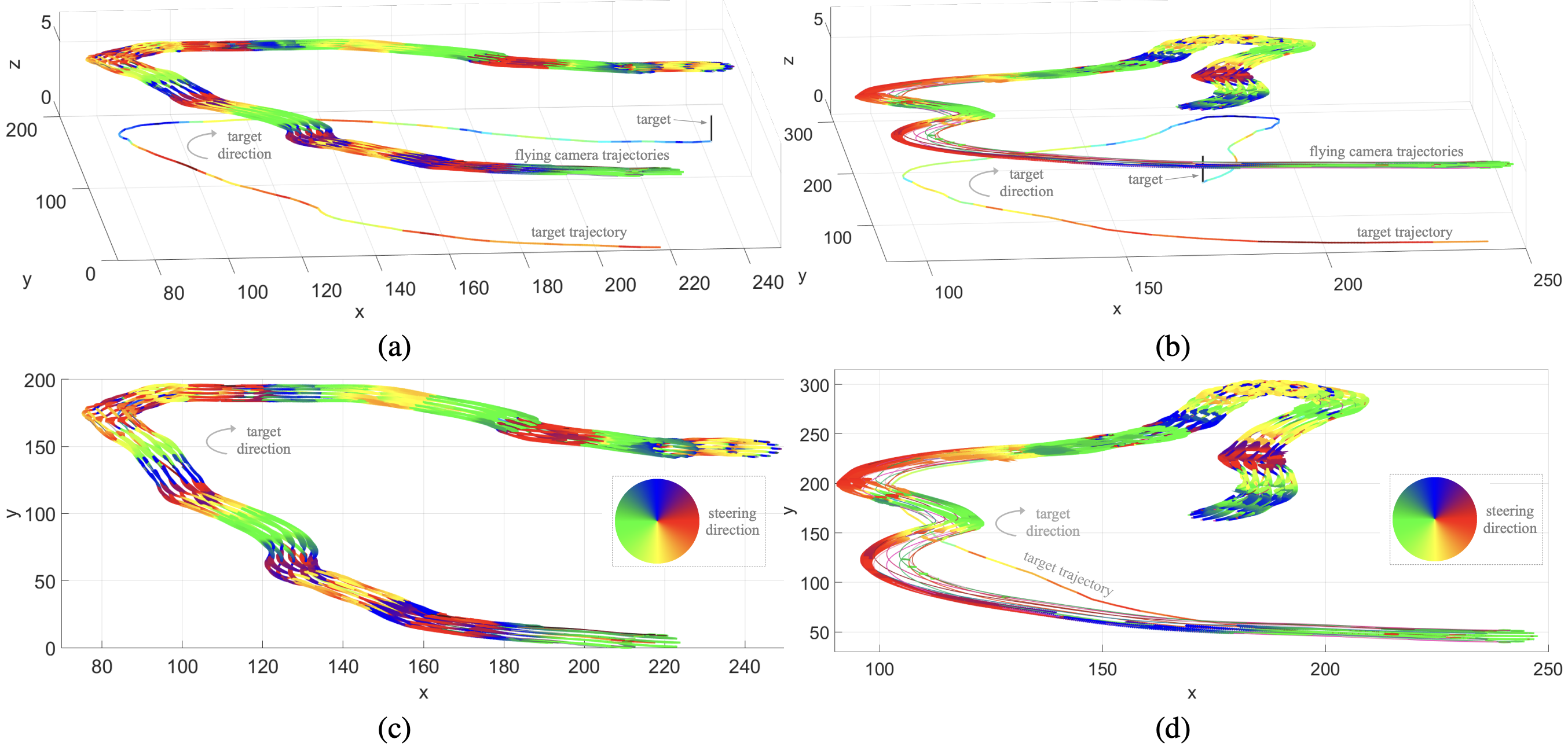
Distributed vision-based flying cameras to film a moving target
Fabio Poiesi, Andrea Cavallaro Intelligent Robot and Systems (IROS), Sep 2015 (video) Infrastructure-free distributed control method for multiple flying cameras tracking a moving object. Our vision-based servoing can deal with noisy and missing target observations, accounts for quadrotor oscillations and does not require an external positioning system. |

|
Detection and tracking of groups in crowd
Riccardo Mazzon, Fabio Poiesi, Andrea Cavallaro Advanced Video and Signal-Based Surveillance (AVSS), Aug 2013 (video) Detecting and tracking interacting people by employing a framework based on a Social Force Model. We model people approaching a group and restrict the group formation based on the relative velocity of candidate group members. |
|
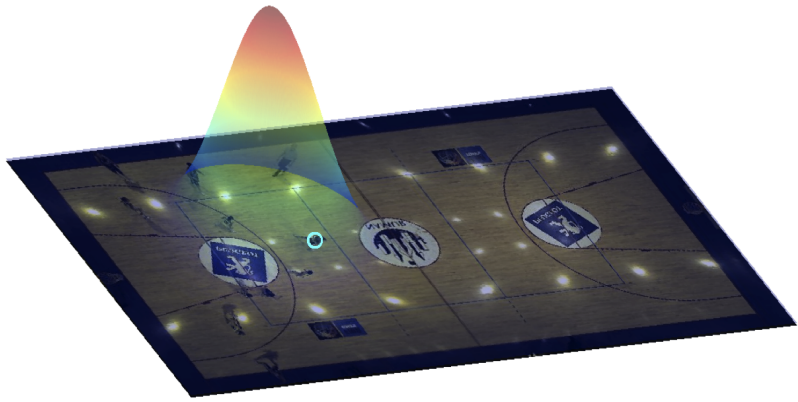
Detector-less ball localization using context and motion flow analysis
Fabio Poiesi, Fahad Daniyal, Andrea Cavallaro International Conference on Image Processing (ICIP), Sep 2010 (video) Estimating the location of the ball during a basketball game without using a detector. We assume the ball is the point of focus of the game and that the motion flow of the players is dependent on its position during attack actions. |
Seminars |
 |
Point cloud deep descriptors and their application to machine perception (video) Shandong University, Jinan, China, Sep 2023 Deep machine vision in digital industry (video) Shandong University, Jinan, China, Nov 2022 Good practices learnt as a young PI (video) University of Trento, Trento, Italy, May 2022 Learning general 3D descriptors for point cloud data Istituto Italiano di Tecnologia, Genoa, Italy, Sep 2020 Localising, understanding and manoeuvring Politecnico di Torino, Turin, Italy, May 2019 H2020 REPLICATE Towards Photogrammetry 2020, Trento, Italy, Jun 2018 Formations of flying cameras to follow and film a moving target Czech Technical University, Prague, Czech Republic, Mar 2016 Formations of flying cameras to film a moving target (video) The London Big-O Meetup, Skills Matter, London, United Kingdom, Nov 2015 Multi-target tracking on confidence maps: an application to people tracking University of Verona, Verona, Italy, Jun 2014 |
|
Feel free to steal this website's source code. Consider using Leonid Keselman's Jekyll fork of this page.
|